LJSpeech is a dataset of actual human voices. Lets start our own subjective quality evaluation by considering the example below.
Modern artificial neural networks can generate credible sounding human speech. A MelGAN-reproduction of the first LJSpeech sentence is hard to identify as such.
The same is true for the HIFI-GAN version below.
The audio is quite convincing. This ability will likely lead to creative new applications for example in video games and movies. Unfortunately, the technology is also abused for theft . In response our paper studies the automatic identification of synthetic speech. We found stable generator-specific fingerprints, and trained networks that generalize well to unknown generators.
The plot below illustrates mean mean level 14 wavelet packet coefficients for LJSpeech and MelGAN-Audio recordings from the Wavefake-Dataset.
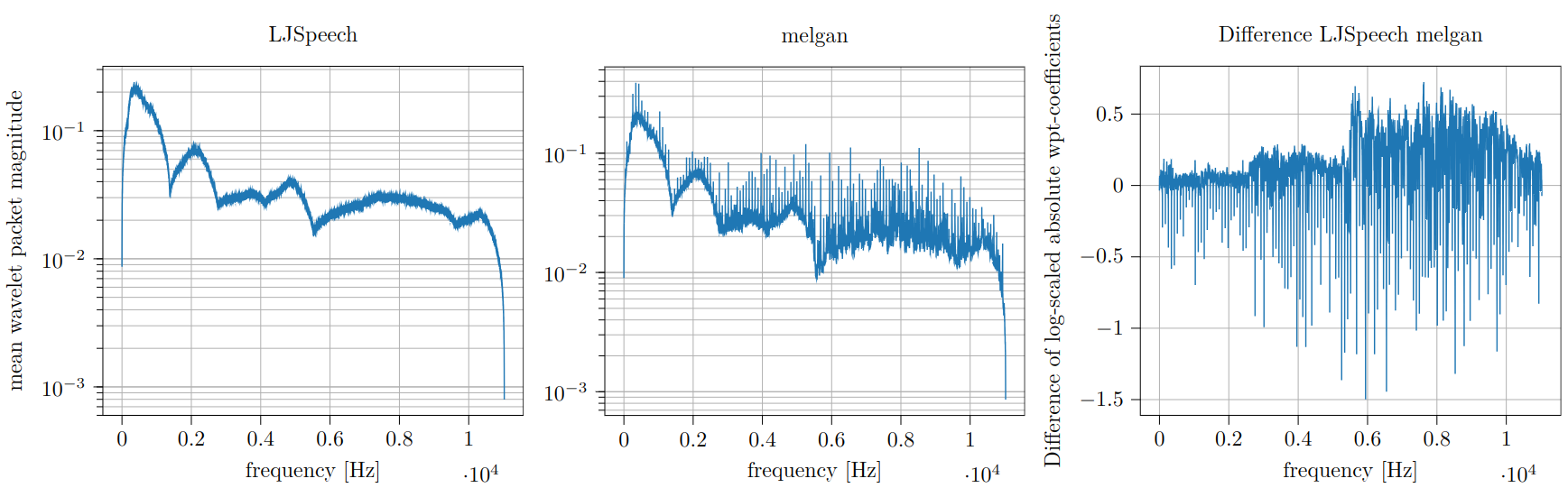
The approach follows Marra et al, they proposed a Fourier-Transform based method to extract deepfake-image fingerprints. We compute some here for the audio deepfake samples collected in the Wavefake-Dataset. If we transform the fingerprints back into the time domain, we can listen to the result! Samples are available below, the results are exciting but not aesthetically pleasing, please set the volume to a low value.
Microphone-fingerprint:
Deepfake ( MelGAN ) – fingerprint:
Deepfake ( HiFiGAN ) – fingerprint:
Deepfake ( Melgan-Large ) – fingerprint:
Deepfake ( Multi-Band-Melgan ) – fingerprint:
Deepfake ( Avocodo ) – fingerprint:
Interested? Our source code and full paper links are available below:
Read more at: https://openreview.net/pdf?id=RGewtLtvHz
Code is available at: https://github.com/gan-police/audiodeepfake-detection/tree/main