During my Master Thesis project I re-implemented Listen, attend and Spell, an attention based speech recognition system. A key problem in speech recognition is that often it is unknown what is said when. In other words the speech signal and its transcription is unaligned. Attention based system such as the one I wrote solve this problem by computing attention weights for each input vector. A visualization of the system is given below:
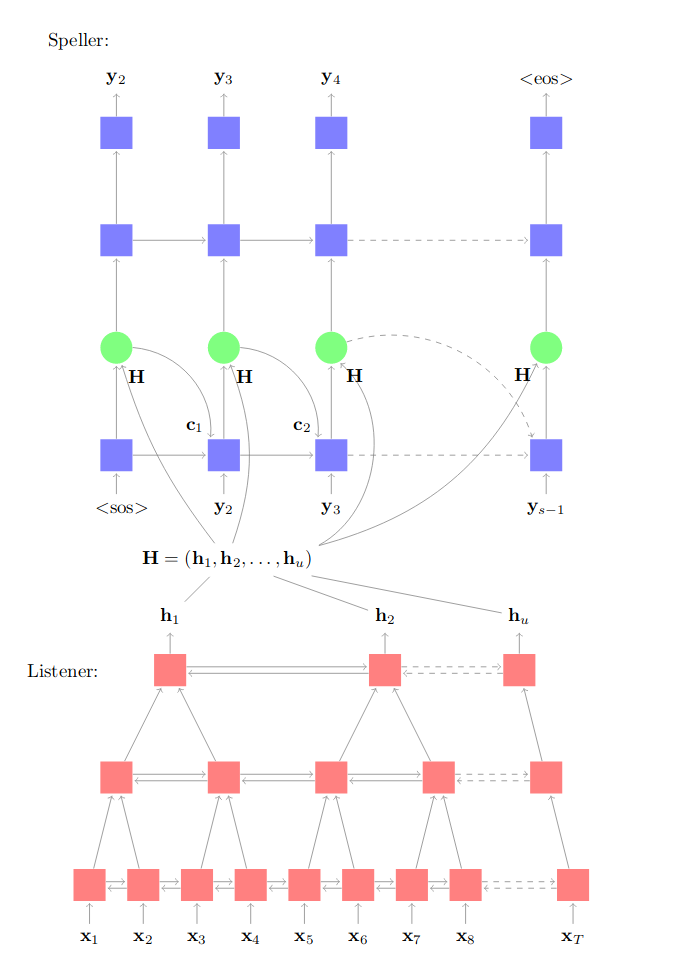
The overall system consists of the two blocks shown in the image above. A listener network computes a compressed fixed length encoding of an input signal. Which is then transcribed to an output sequence by the speller. To come up with a transcription the speller has to compute attention weights such as those shown below:
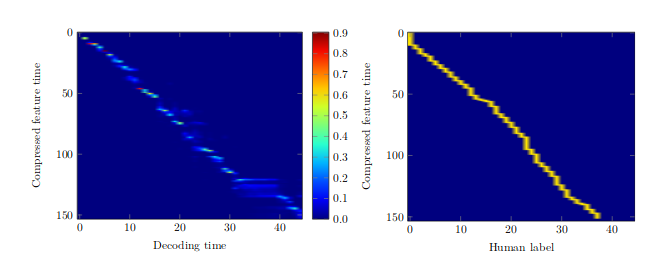
The plot above reveals that the attention weights found be the network are quite similar to those assigned by a human listener. Some artifacts remain, but its must be kept in mind that TIMIT is a quite small data set. Better results have been observed when larger data sets and more that just a single 8GB graphics card are used for training.
The source code is available on github.
For an in depth discussion please take a look at my thesis text.
The links below lead to more samples of my work on support vector machines and data-mining:
More on svms
More on data-mining